Big ideas in machine learning, simply explained
The rapidly increasing usage of machine learning raises complicated questions: How can we tell if models are fair? Why do models make the predictions that they do? What are the privacy implications of feeding enormous amounts of data into models?
This ongoing series of interactive essays will walk you through these important concepts.


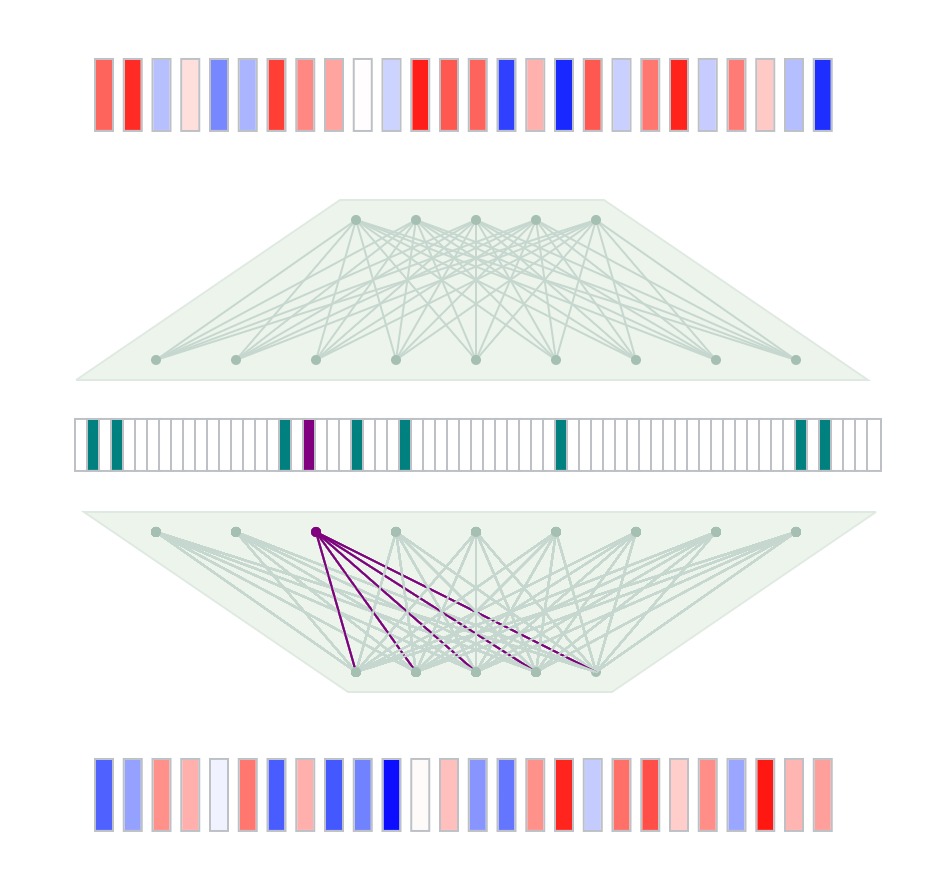
An introduction to Sparse Autoencoders, a technique to unpack and understand the hidden representations of LLMs.

An introduction to Patchscopes, an inspection framework for explaining the hidden representations of LLMs, with LLMs.

An introduction to grokking and mechanistic interpretability.
By asking language models to fill in the blank, we can probe their understanding of the world.

ML models sometimes make confidently incorrect predictions when they encounter out of distribution data. Ensembles of models can make better predictions by averaging away mistakes.
The availability of giant datasets and faster computers is making it harder to collect and study private information without inadvertently violating people’s privacy.

Machine learning models use large amounts of data, some of which can be sensitive. If they’re not trained correctly, sometimes that data is inadvertently revealed.

Training models with differential privacy stops models from inadvertently leaking sensitive data, but there’s an unexpected side-effect: reduced accuracy on underrepresented subgroups.

Most machine learning models are trained by collecting vast amounts of data on a central server. Federated learning makes it possible to train models without any user’s raw data leaving their device.

Machine learning models express their uncertainty as model scores, but through calibration we can transform these scores into probabilities for more effective decision making.

Machine learning models sometimes learn from spurious correlations in training data. Trying to understand how models make predictions gives us a shot at spotting flawed models.

Every dataset communicates a different perspective. When you shift your perspective, your conclusions can shift, too.

Search results that reflect historic inequities can amplify stereotypes and perpetuate under-representation. Carefully measuring diversity in data sets can help.

There are multiple ways to measure accuracy. No matter how we build our model, accuracy across these measures will vary when applied to different groups of people.
Models trained on real-world data can encode real-world bias. Hiding information about protected classes doesn’t always fix things — sometimes it can even hurt.




